图像检测工具包

使用简单可靠且功能强大的 SaigeVision® 平台来自动化您的视觉检测任务。 SaigeVision® 采用最先进的机器学习算法,以及先进的数据生成、增强和标记工具,可为最具挑战性的检测问题提供无与伦比的准确性和速度。 即使只有有限的训练数据,SaigeVision® 也能以最低的运营开销实现最高的性能。
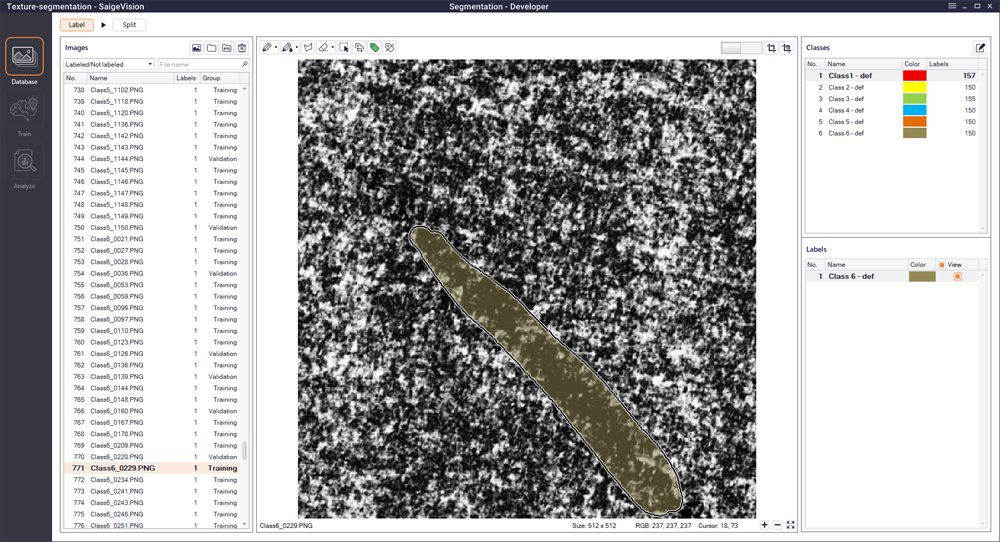
特色
快速
结合最佳迁移学习构建稀疏网络、高级模型压缩和修剪、以及算法优化,SaigeVision® 实现了毫秒级的检测速度。 并且通过“集中注意力学习”,大大减少了训练模型的时间。
灵活
SaigeVision® 旨在实现直观、模块化、可扩展且易于集成和部署。 各种标记的工具大大减轻了用户准备和训练神经网络模型的负担。 用户不需要视觉系统和编程方面的专业知识就可以完全掌握和操作SaigeVision®。
准确
SaigeVision®通过结合我们专利的图像生成技术、自动标记技术,以及其他先进的机器学习技术,实现了世界一流的检测准确率。在实际生产中,过杀率和漏检率都显著降低。
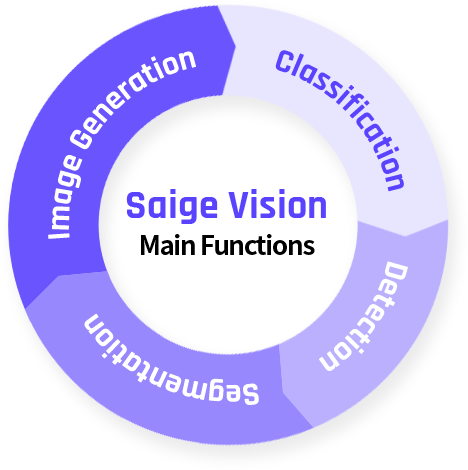
主要功能
-
分类 Classification
快速判断一个样品是正常还是有缺陷 -
检测 Detection
确定缺陷的类型和位置(使用边界框) -
分割 Segmentation
确定缺陷的类型和位置(像素级轮廓) -
图像生成器 Image Generation
生成用于训练神经网络的虚拟缺陷图像
配置要求
级别
最低配置
推荐配置
操作系统
Windows 7 64-bit / Windows 10 64-bit
中央处理器
Intel Core i5
Intel Core i7
开发环境
Visual Studio 2013
Visual Studio 2013
内存
16GB
32GB
显卡
NVIDIA GeForce RTX 3060, 3070
NVIDIA GeForce RTX 3080, 3090
硬盘
SSD
软件特点
1. 最优迁移学习和定向注意力学习
- 通过设计一种优化转移权重的“转移学习算法”,训练时间大大减少。同时生成稀疏、易于修剪的网络
- 我们的“定向注意力学习算法”专注于学习更重要的缺陷区域

2. 图像生成技术
-
数据不足的问题深度学习网络的性能与训练所用的数据息息相关。 数据越多,数据越丰富,性能就越好。 然而现实是大多数用户的数据非常有限,尤其是有缺陷的样本。
-
图像数据生成技术合成数据其实比分析数据更棘手。对现有的缺陷样本图像进行简单操作,例如:翻转、旋转、模糊,这些对训练模型都没有显著的帮助。 想要生成逼真的缺陷图像需要更复杂的技术。
-
基于 GAN 的图像数据生成SaigeVision® 为了合成最真实的缺陷图像,SaigeVision® 利用内部开发的先进 GAN技术,生成为工业图像检测应用定制的合成数据。以此来提升神经网络模型的性能。

优势
提高了检测的准确性
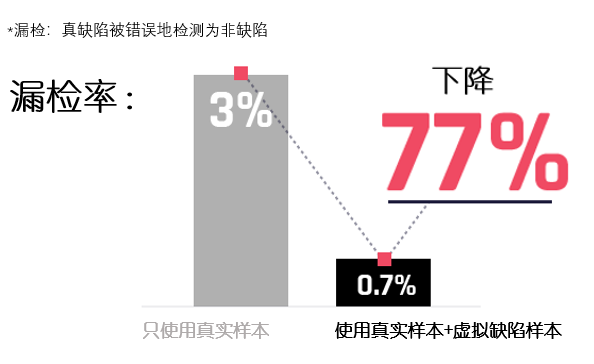
提高了部署效率

使用图像生成器来检测新产品或新生产线
-
使用类似产品训练GAN模型
-
使用训练出的GAN模型 为新产品生成虚拟合成图像
-

使用合成图像 训练新产品的检测模型
-
使用训练出的检测模型 进行实时检测
-
生成真实生动的合成图像数据SaigeVision® 利用生成对抗网络 (GAN) 生成缺陷的合成图像,这些图像与实际缺陷几乎无法区分,即使肉眼看也是如此。可以在任意位置生成各种缺陷类型和尺寸,同时保持背景均匀性。

-
可靠的GAN图像训练众所周知,GAN方法在实践中难以应用。 训练 GAN网络可能很耗时,并且相对不稳定。 SaigeVision® 使用针对工业检测优化的内部算法克服了这些挑战,为真实场景提供了最优异的性能。

-
能快速部署在新产线深度学习解决方案的好坏取决于它们所训练数据的质量和数量。 使用我们的 GAN 生成的图像数据,甚至可以对尚无数据的新产品进行训练。并且提前部署在生产线上。
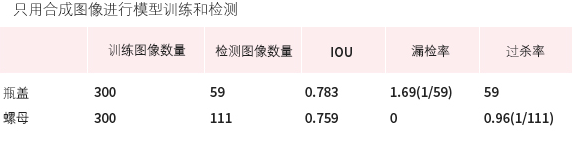
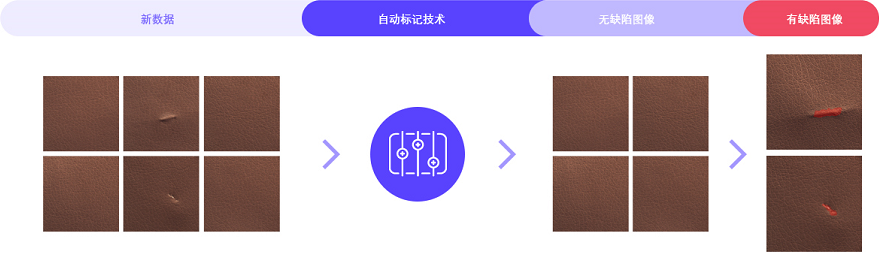
3. 自动标记技术
- 对于大多数工业检测任务是由企业质检人员进行图像标记。 这项任务很耗时,而且人类容易疲劳和误判。 由于大部分训练数据来自无缺陷样本,因此可以使用自动标记来识别那些无缺陷的图像,将这些图像与数量更少的可能包含缺陷的图像分开。 然后质检人员只需要检查和标记这组小样本即可。