


Date: 2021.07.20.
Writer: Hyeokjun Kwon
Source: Saige Blog – A Peek into Automatic Data Augmentation by Policy Searching
Machine-learning(ML, 기계학습) 혹은 Deep-learning(DL, 딥러닝) 기반으로 모델을 학습할 때 data augmentation(DA, 데이터 증강)은 모델의 generalization(일반화) 성능과 좋은 representation 학습에 있어서 매우 중요한 기술입니다. 하지만 이 data augmentation은 주로 사람의 경험이나 직관에 크게 의존하고 있습니다. ML/DL community에서도 이러한 문제를 인식하고, 효과적으로 data augmentation을 자동으로 수행하기 위한 연구들이 있어왔습니다. 이번 글에서는 엔지니어에 대한 의존성을 제거하고 data-augmentation을 사람보다 효과적으로 수행하기 위해 연구되고있는 갈래 중 하나로서, “탐색”기반 접근법인 automatic augmentation policy searching에 대해 다루어보고자 합니다.
먼저 deep-learning에서 data augmentation의 중요성을 알아본 후, 최적의 data augmentation을 자동으로 수행하기 위한 automatic data augmentation란 무엇인지 소개하고, 그 중에서 Automatic augmentation policy searching에 관련된 주요 연구 5개를 순서대로 소개하는 것으로 마무리하고자 합니다.
Deep-learning에서의 data augmentation
Data augmentation과 필요성
DL에서 Generalization
DNN(Deep Neural Network)은 매우 felxible한 universal function approximator입니다. 때문에 주어진 데이터셋을 이용해 DNN 모델을 학습할 때, 학습 데이터 셋에 쉽게 과적합(Overfitting) 되어버리게 됩니다. Overfitting이 일어나면, 학습한 데이터셋에 대해서는 성능이 매우 우수할지라도, 저희가 보기에는 비슷하지만, 학습에 없었던 데이터셋(test dataset)에 대해서는 성능이 잘 나오지 않습니다. 이를 overfitting이라는 말 대신, 일반화(generalization) 성능이 좋지 못하다라고 말하기도 합니다.
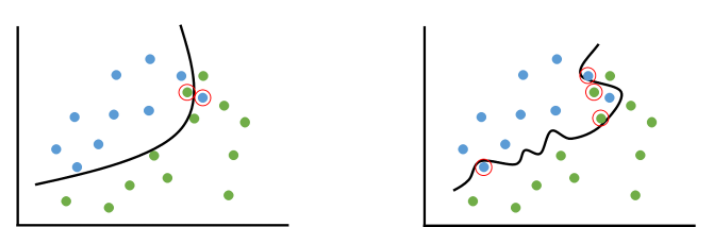
Figure 1. 적절히 fitting된 모델(좌)과 overfitting된 모델(우). (출처: https://untitledtblog.tistory.com/158)
Overfitting이 일어나는 근본적인 이유는 DNN 모델의 capacity(felxiblity와 유사합니다.)가 일반적으로 주어지는 학습 데이터셋에 비해 너무 크기 때문입니다. 이러한 경우, 쉽게 말해서 DNN은 단순히 학습 데이터들을 “외워”버리게 됩니다. 학습 데이터셋이 작기 때문에 이를 다 외워서 풀 수 있고, 굳이 데이터에 내재된 특징들을 배우려하지 않습니다. 단순히 학습 데이터셋을 외워서 문제를 잘 푸는 모델은 학습 데이터셋에서 조금만 다른 데이터가 들어오면 제대로 문제를 풀지 못합니다.
때문에 DL 기반으로 학습된 모델을 실제로 사용하기 위해서는 generalization이 매우 중요합니다. 이를 해결하기 위해서 많은 연구들이 이미 진행되었고, 그 중 매우 기본적이지만, 효과적인 방법이 data augmentation 입니다.
Data augmentation
앞서 overfitting이 일어나는 근본적인 이유가 DNN 모델의 capacity에 비해 주어지는 학습 데이터셋이 작기 때문이라고 말씀드렸습니다. 만약 데이터가 무한정 주어진다면, overfitting 문제는 존재하지 않습니다. 하지만 이는 실제로 불가능합니다. 무한정 많은 데이터가 주어질리도 만무하고, 있다하더라도 유한한 시간안에 무한정 많은 데이터로 모델을 학습하는 것은 불가능합니다.
무한히 많은 데이터를 얻을 수 없는 대신, 주어진 데이터를 가지고 이를 적절히 잘 불려서 학습에 사용하는 접근법이 바로 data augmentation입니다. Figure 2에서 볼 수 있듯이, 한장의 코알라 사진만으로도, 수 없이 많은 다른 이미지들을 생성할 수 있습니다. 물론 저희가 인식하기에는 같은 사진에 ~~장난질?~~만 해둔 것처럼 보이기는 하지만, DNN 입장에서는 모두 다른 숫자로 이루어진 데이터입니다. DNN한테 이러한 augmentation된 수 많은 코알라 이미지들을 “코알라”로 분류하도록 학습시키면, DNN은 이 이미지들로 부터 공통된 특성을 찾고, 그것을 “코알라”이라는 분류가 가져야할 특징으로서 학습하게 됩니다. 이로서 DNN은 단순히 데이터를 외우는 것이 아니라, 데이터셋에 내재된 특징을 학습하고, overfitting을 피하게 됩니다.

Figure 2. data augmentation. (출처: https://github.com/aleju/imgaug)

Figure 3. sliding puzzle (출처: “슬라이딩 퍼즐”, Google image)
그렇다면, figure 2의 방식으로 data augmentation을 무작정해서, 모델을 학습시키면 overfitting을 잘 막을 수 있을까요? 당연히 그렇지 않습니다. 너무 강한 data augmentation은 오히려 모델에 혼란만 가중시킬 수 있습니다. Figure 3에 있는 슬라이딩 퍼즐을 보고, 퍼즐을 맞추었을 때, 어떤 캐릭터가 있는건지 쉽게 상상이 가시나요? 맞추셨더라도, 지금은 $4\times4$이지만, 만약 $8\times8$이 되어도 맞출 수 있을까요? 아마 쉽지 않을 것 같습니다. 이는 퍼즐이 어려워짐에 따라, 원래 그 캐릭터가 가지고 있던 중요한 특성들이 없어져버리기 때문입니다. 이처럼 무분별한 augmentation은 데이터가 원래 가지고 있던 특성을 파괴해서, 오히려 학습에 불안정성을 증가시킵니다. 또한 특히 이미지 데이터의 경우 CNN(Convolutional Neural Network)라는 모델을 많이 사용하는데, 이 종류의 모델은 이미지의 지역적인 특성(선, 특정 패턴, 등)을 잘 학습하는 특징이 있습니다. 하지만 figure 3와 같은 augmentation은 이미 원래 이미지의 지역적인 특성을 잃어버린 것 같군요. 이러한 이미지로는 CNN이 유의미한 정보를 학습하기 어렵습니다. 물론 테스크에 따라 이러한 augmentation이 도움이 되는 경우도 있지만, 이 또한 task specific하다는 문제가 있습니다.
그렇다면 내가 하려는 어떤 테스크(task)에 대해 잘 맞는 어떤 적절한 augmentation은 도대체 무엇일까요? 이를 정확히 알기는 아마 불가능할 것 같습니다. Data augmentation은 거의 무조건 쓰이는 중요하고 기본적인 기법이기는 하지만, 실제 적용할 때는 잘되는 것 같은 “적당한” augmenting operation을 사람의 “직관”과 “경험”에 의존하여 사용합니다. 그것으로 충분할 수도 있지만, ML/DL community의 연구자들은 이를 용납하지 않았습니다. 이들은 “적당한 data augmentation을 찾는 문제”를 다시 ML/DL 방법론으로 해결하고자 하고 있습니다. 그것이 바로 이 글의 주제인 automatic data augmentation입니다.
Automatic Data Augmentation
제가 생각하기에 data augmentation 연구는 대략 아래와 같이 4가지로 나눌 수 있습니다.
- Data augmentation
- Single operation
- Manually designed single operation: 엔지니어의 직관과 경험에 의해 설계된 augmenting operation
- Automatically designed single operation: Augmentation network를 두고, 엔지니어는 loss function만 정의해서 network가 스스로 augmentation을 학습
- Combination of operations (Augmentation policy)
- Manually designed augmentation policy: 엔지니어가 hand tunning 😱. 연구라기 보다는 application에 가깝습니다.
- Automatic augmentation policy searching: Search algorithm을 사용해서 주어진 데이터와 테스크에 대한 최적의 augmentation policy(augmentation의 조합)을 탐색
- Single operation
Manually~라고 시작하는 분류는 이번 글의 관심사가 아닙니다. 앞서 엔지니어가 직접 augmentation을 디자인하거나 결정하는 것이 어려운 문제임을 충분히 설명하였습니다. 그렇다면 automatic data augmentation에 속하는 남은 두가지 분류에 대해서 간략히 소개해보도록 하겠습니다.
Automatically designed single operation은 엔지니어의 직관이나 경험에 의해 설계된 augmenting operation이 아닌, augmentation을 위한 DNN (augmentation network)을 따로 두고, 엔지니어는 단지 augmentation network를 학습하기 위한 적절한 목표(objective function or loss function)만 정해주어 DNN 스스로가 좋은 augmentation을 만들어내는 augmentating operator가 되도록 학습시키는 방식입니다. 여기에 속하는 많은 연구들이 있지만, 이번 글에서는 다루지 않습니다.
Automatic augmentation policy searching이 바로 이번 글의 주제입니다. 데이터셋과 테스크가 주어졌을 때, augmentation network 없이, 기존에 있는 augmenting operation(rotation, invert, shearing, color jittering, cutout, 등)들을 어떻게 조합하면 최적의 augmentation이 가능한지를 자동으로 탐색하는 방식입니다. Automatic augmentation policy searching이라는 이름은 augmenting operation을 조합하는 정책을 탐색한다는 의미에서 제가 붙혔습니다.(편의를 위해 이번 글에서 이렇게 쓰겠습니다.) 참고로 이후의 내용에서 augmentation policy라고 말하는 것들은 reinforcement learning의 agent의 policy와는 다른 개념입니다. 오히려 augmentation policy는 RL agent의 policy로 부터 샘플링된 하나의 stochastic action으로 보는게 맞습니다.
이 분류의 문제 상황이나 자세한 내용은 세이지리서치 Notion에 페이지에서 논문을 보면서 다루어보도록 하겠습니다.
세이지리서치 Notion – A Peek into Automatic Data Augmentation by Policy Searching
Conclusion
이번 글에서는 Deep-learning에서의 data augmentation 기법의 중요성과 한계점을 살펴보고, 한계점을 다시 ML/DL 방법론으로 풀려고하는 automatic data augmentation이라는 분야 중 Automatic augmentation policy searching 방법론에 대한 연구 5개를 살펴보았습니다. 저도 최근에야 관심이 생겨 보기 시작한 분야의 연구들이었기 때문에, 각 연구의 배경이나 숨은 의미까지는 충분히 담아내지 못했을 수도 있지만, 읽어보시면서 automatic data augmentation이 왜 필요한지, 어떻게 문제를 정의하고 풀어낼 수 있는지, 각 연구들이 선행 연구를 어떻게 개선해나갔는지에 대해서 알게되셨기를 바랍니다.
또한 오늘 소개한 연구들이 대부분 이미지 데이터에 집중되어 있었는데, ML/DL에서 다루는 주요 데이터가 이미지인 것은 맞지만, 이 연구들의 방법론이 이미지에만 국한된 방법론이라고 생각하지는 않습니다. 따라서 search based autmated data-augmentation이 다른 데이터에 대해서는 어떤식으로 적용되는지 알아보는고, 데이터의 특성에 따른 차이를 automatic data augmentatoin 방법론에 포함시킬 수 있는지 생각해보는 것도 재밌을 것 같습니다. 읽어주셔서 감사합니다! 😁
Reference
- **AutoAugment: Learning Augmentation Policies from Data, CVPR 2019**
- **A survey on Image Data Augmentation for Deep Learning, Journal of Big Data 2019**
- **Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules, ICML 2019, GitHub**
- **Fast AutoAugment, NeurlPS 2019,** GitHub
- **DADA: Differentiable Automatic Data Augmentation, ECCV 2020**
- **RandAugment: Practical Automated Data Augmentation With a Reduced Search Space, NeurIPS 2020**
- **Learning Data Augmentation Strategies for Object Detection,** ECCV 2020
- Population Based Training of Neural Networks, arXiv 2017
- Bayesian optimization, Wikipedia
- Gumbel softmax
- Backpropagation through the Void: Optimizing control variates for black-box gradient estimation, ICLR 2018